KV-Cache Reuse in Large Language Models
An exploration on sparse attention and KV-Cache optimization for language models.
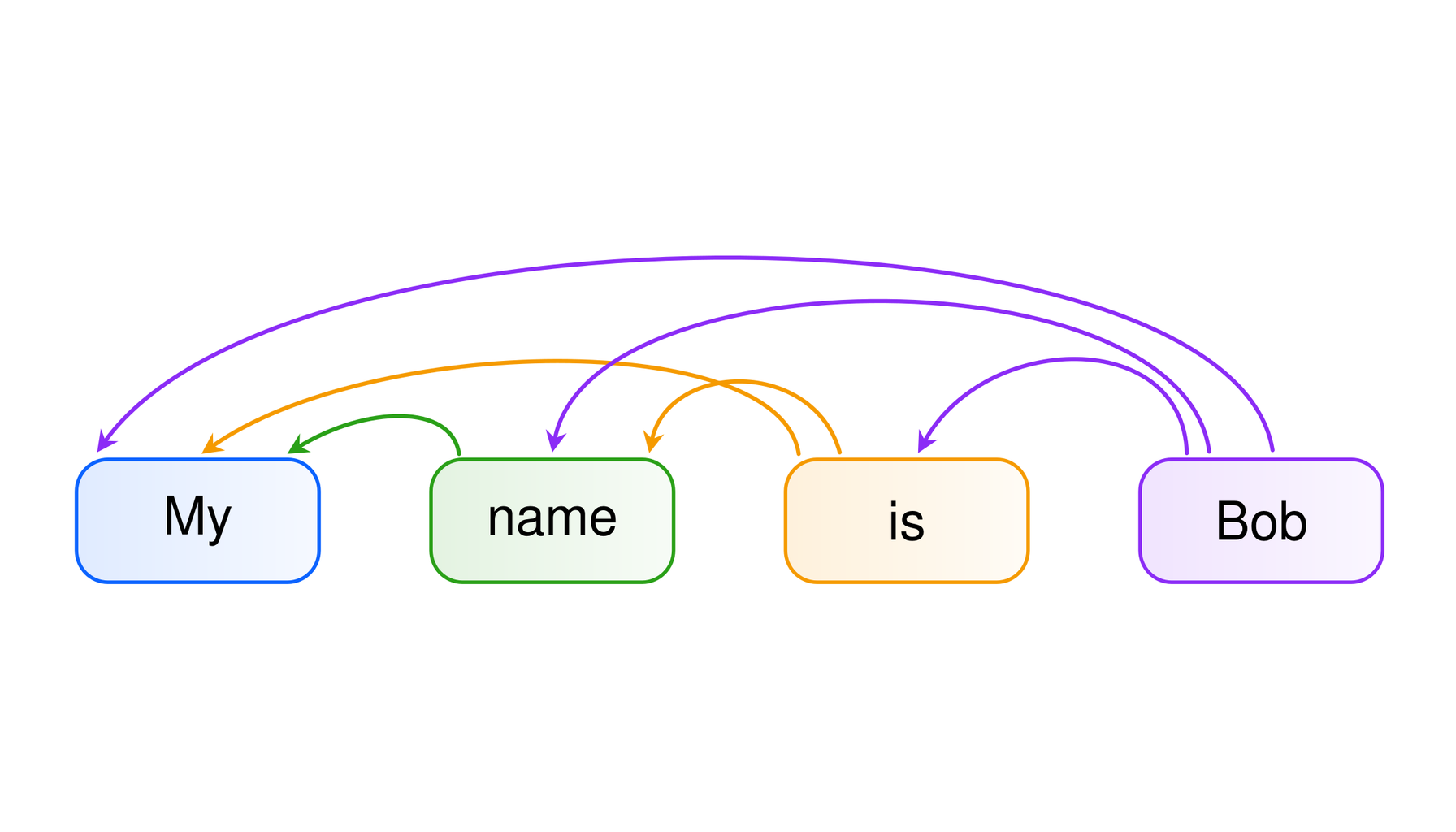
The transformer archiecture in language models has popularized the self-attention mechanism. This mechanism consists of three key components:
- Key: A label for the previous tokens, describes what they contain
- Value: The actual information or context that is stored
- Query: The question being asked about the preceding text, this information is not cached
For example, let's say that the preceding context consists of the phrase "My name is Bob", tokenized by word.
Each token attends strictly to itself and its preceding tokens. This is enabled by an attention mask, which determines which tokens are attended to.
Large language model inference consists of two stages: the prefill and the decode stages. The prefill stage processes the context and creates the initial KV-cache, while the decode stage autoregressively generates the output token based on the previous context. During the prefill stage where the KV-Cache is generated, the attention weight for each token is generated by attending to all previous tokens. This would be computationally expensive if we had to recompute from scratch each attention weight. Instead, we can use the KV-Cache to speed up the process. The intermediary key and value cache can be stored and later used to calculate these attention weights. By storing the key and value for previous tokens, we no longer have to restart the attention weight calculation for every new token.
Even with these optimizations, inference times are still bottlenecked by the prefill phase. There are different methods for speeding up inference, one obvious optimization is not to attend to all previous tokens, only the ones that are most relavent to the current token (caculated through an attention score), this is called sparse attention.
A simple but effective method of sparse attention we will investigate is called block attention. In block attention, we chunk the context into separate chunks (these could be separate documents or turns in a chat window). Within each chunk, each token attends to only itself and other tokens.
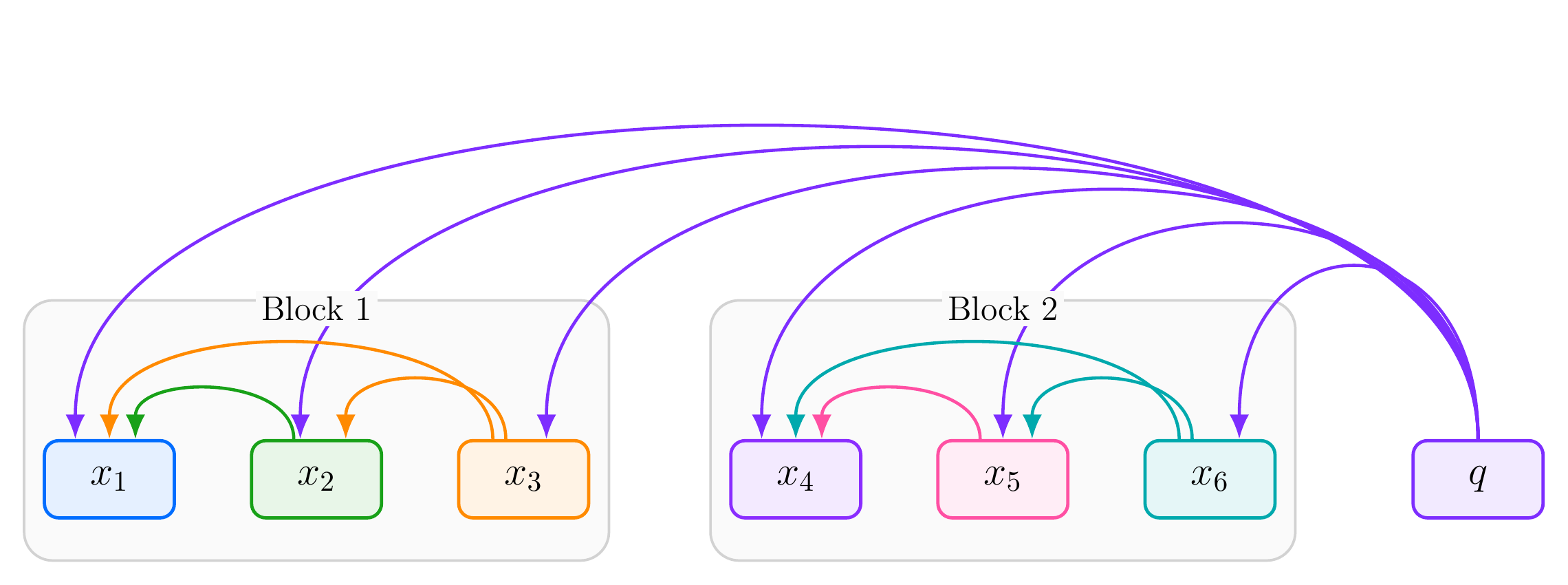
Block attention be immensely useful in conjunction with augmented generated retrieval. However, block attention does come with some deficits. One of which being that distant relationships across block boundaries are degraded. To fix this post-processing steps are often required.